最近读完了日文版的“海边的卡夫卡”
之前完全没有看过中文版的,连剧情简介也没有看过。
但因为自己开始学日语的关系,学有小成之后开始拿这本小说练手,天哪,太好看了。
下面主要说说我是怎么学日语的。从一个程序员的角度出发,日语不就是另一门语言吗。
以前在大学的时候上过一学期的日语选修课,因此知道50音表,和少量的词汇。
这次开始学习之后,先在Linux下学了一下如何进行日文输入。这个在Emacs底下有一个SKK的输入法,并且后来也被移植成ibus、scim等的插件了,所以花了点时间,练了练,马上就掌握了。
然后,开始折腾Linux下的日文字典,不管是桌面软件,还是网页形式的。这里桌面版的推荐一个 Gjiten。网页版的字典则推荐 http://jisho.org、 谷歌翻译、 维基字典日文释义、 最后一个则是对发音重读音节非常有帮助的 东京大学的一个网站。 在用Gjiten的过程中,发现它有很多词语类型、词性的缩写,然后上网搜都是什么意思的时候,发现日本人做事情真的是好严谨,有一个专门的网页解释这些缩写: 日文字典缩写代码。
接下来程序员的特质开始展开了。先是日文输入的问题。有时候想输入个日文汉字,因为不知道其读音,所以用日文输入法并不是太方便。想用中文输入法吧,日文汉字并不能简单的用简繁转换来映射。最早的时候日文汉字基本上就是繁体字,但后来跟中文简体字一样,日本人也对他们的汉字做了一些简化,有些与中文简体字的简化结果是一样的,但也有很多是不一样的。很多中文输入法是支持切换简繁体的,但并没有哪个支持切换成日文汉字的输出。比如簡体的“亚”字,如果是繁體的話,應該輸出成“亞”,但如果是日語的話,応該輸出成“亜”。
後来我研究了一下byvoid (微博) 的 opencc 项目,并加了一些 修改 , 支持了简体汉字与日文汉字之间的转换。然后将其加入了我的影舞笔输入法(切换方法及其奇葩,通过输入 ;!s ;!t ;!j 来进行简、繁、日的切换,并没有什么图形界面,反正本来也只有我自己用)。
然后,在研究上面的日文字典缩写代码的时候,突然发现有个代码很有意思,叫 “P”,代表 Priority 的意思,优先级比较高,属于常用单词的会带这个代码。所以,我就看了一下 Gjiten 的字典数据,把所有常用单词都抽出来了,每天从中抽100个单词进行学习,学习的方法是放到 Emacs 的 org-mode 里,所有的生词一开始都是 TODO ,还没有学的,如果我看了这个单词,已经学会了,就标为 DONE ,如果还没有学会,就标为 SOMEDAY 。现在已经掌握5000多个单词了。后面还有15000个左右要学的。这就是我的日文“百词斩”了。
学着学着,突然又开了一下程序员的脑洞,就是日文汉字是分音读和训读的,训读咱先不说,那是日本人自己本来的读法;音读,那跟中文发音是有很深的历史渊源的,基本上相当于古汉语的发音方法。所以很自然的,我想到了要把所有拼音相同的汉字列出来,然后对比它们的日语音读发音。前者的数据可以从影舞笔的数据中得到(最早应该是从海峰五笔里拿来的);后者也可以从Gjiten的字典数据里得到。然后写了一个 kanji-pinyin-lookup 的脚本,允许我输入拼音,然后它输出所有相同拼音的汉字的日文音读。比如汉字的 “han”,

可以看到几乎所有的中文 han 字,日文读音都是 カン (拼音kan)。又比如汉字的 “zi”,
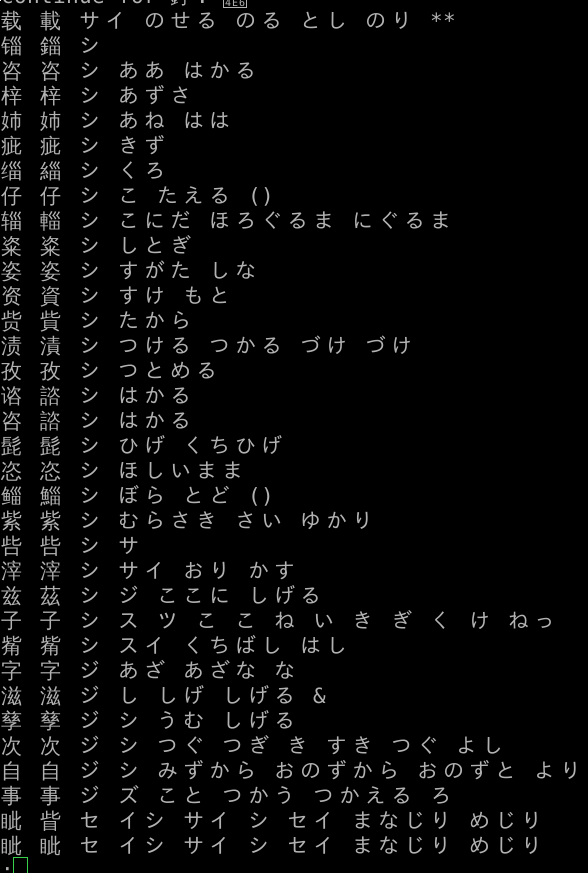
可以看到大部分读 し (拼音xi) ,小部分读じ (拼音ji)。
这下我学起日语单词来,那可就如虎添翼了啊。导致我现在掌握的5000多个单词中,90%都是汉字词语。既知道如何发音,又知道大概意思,在我看来就算掌握了。
并且很快我总结出来一些规律,挺有意思的,比如几乎所有的拼音前鼻音,在日语里都是鼻音(ん);几乎所有的拼音后鼻音,在日语里都是长音。所以像日语里的“先生(せんせい)”、“天空(てんくう)”,它們的発音為什麼是鼻音+長音,就很好理解了,以前我覚得経常会搞混的。
所以看本“海边的卡夫卡”基本不是什么问题。好了,今天就聊到这儿,刚刚下完了一本动作爱情片,我先去练会儿日语听力。
日本語の勉強は、とても面白いね。
